Unless you’ve had your head in the sand, you’ve seen how Webpack 5 Module Federation has enabled true micro front-ends, allowing SPA’s to share components between individually deployed services. This allows for “Service A” to deploy with an update to “Service A/SharedComponent”, while “Service B” receive the update to the shared component without a deployment of it’s own.
This is arguably really cool, but Module Federation allows us to apply this idea to back-ends and work in what I’m calling a “noservice” architecture.
WTF is a noservice?
Before we jump into what a noservice is, let’s review the microservice architecture through the lens of Apollo Federation. An Apollo Federated Graph consists normally of a single “Gateway” that is responsible for receiving a query from a client then delegating parts of that query out to your microservices to fulfill the request.
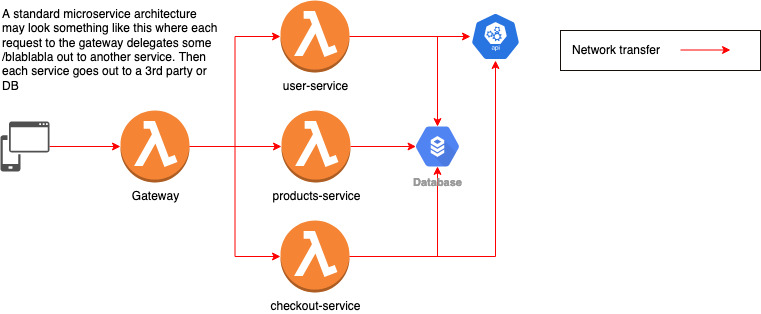
One issue with this type of approach comes when you have multiple microservices interacting with the same external services / databases, leading each microservice to load / fetch duplicate data.
The noservice architecture enables each team to work autonomously in their own repositories, just like in a microservice architecture, while sharing the same runtime at the gateway enabling us to not just get rid of network requests to microservices, but also share dataloaders throughout the execution of each query from the gateway to the noservices.
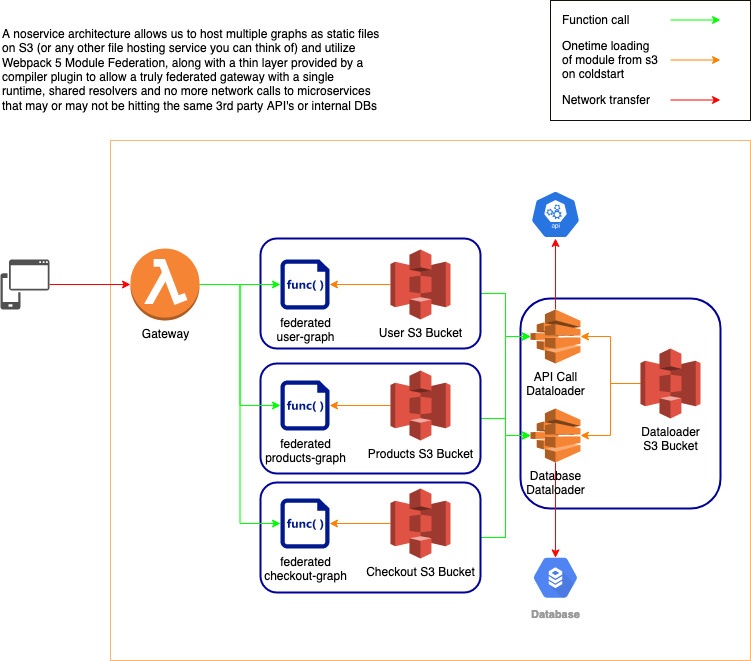
We can define a noservice as a piece of code, however big or small, that is dynamically loaded by a host and executed in a common runtime.
The above architecture diagram demonstrates how a noservice architecture may look in an AWS stack. A key things to note here is the only lambda that is running is the “gateway”. On cold-start, the gateway goes out to a few S3 buckets, and in parallel, retrieves the 4 noservices: user, products, checkout, and the shared dataloaders (note that the source of the noservices can be any static file hosting service).
As with the microservice architecture, we are accomplishing the same overarching goal of creating a Federated Graph with each team responsible for developing and deploying their portion of the graph, but instead of 4 separate lambdas all cross communicating, we have a single runtime, a single set of dataloaders, and only a single call to external APIs or databases no matter how many noservices load that data per request.